Over the next few days you will see my Data Protector online store add some new products:
As it turns out, even though they are sold from store.data-protector.net, these Training Units can be used for just about anything (e.g. the new HP Records Manager (HP RM) / TRIM e-learning modules, face-to-face courses at HP, VILT classes.)
Greg Baker is an independent consultant who happens to do a lot of work on HP DataProtector. He is the author of the only published books on HP Data Protector (http://www.ifost.org.au/books/#dp). He works with HP and HP partner companies to solve the hardest big-data problems (especially around backup). See more at IFOST's DataProtector pages at http://www.ifost.org.au/dataprotector, or visit the online store for Data Protector products, licenses and renewals athttp://store.data-protector.net/
Friday, 27 November 2015
How to avoid getting lumped with the tickets that take forever to resolve -- Sydney Atlassian Devops Groups
For those that were (and those that weren't) at the Sydney Atlassian Devops Meeting last night, my presentation is here: http://prezi.com/ukofmue_rgf0/
Devops poetry

Everyone I know in Devops
Perl is no worry, and I grok Ruby gems;I've wrestled a Python or two;
I've built an app (along with a friend)
And run a VM with Haiku.
I've written Java and downloaded Go;
And Haskell, I love -- it's a joy.
Ansible, Salt and Chef, those I know:
I'll debug a Cloudfront deploy.
I've found a bug in an enterprise app,
By strace'ing through its coremem dump.
I've patched up live a signal break trap
To fix up a subroutine jump.
Storage and routers and syscalls are fine,
Also VOIP service call groups.
Mapping, reducing, data refined:
I set up the office Hadoop.
I am SRE -- I will fix anything:
Deploying it twice in an hour,
Split loads across sites based upon ping,
Google is awed at my powers!
So why am I stumped and lost more or less
With a bug that I cannot mend?
Please help if you can, because I confess
Yes, docker is crashing again.
Wednesday, 25 November 2015
When Medusa went on Chatroulette
And now for something completely different: my poetry collection is now available for pre-order from Amazon.
They are all happy and cheery poems about technology, geekdom, nuclear physics, time travel, first contact and all the really important things in life. There are no soppy love poems, and no heart-felt tales of loss. These poems will make you smile and laugh and then ponder for a little while if you feel like it. At the very least, if you're a geek-nerd kind of person, they will lighten up your day.
It's a nice Christmas present for the geek in your family. Or a colleague. Or you can treat yourself.

Pre-order link: Amazon.
Warning: these poems are totally unsuited to liberal arts majors as they won't understand most of them. Recommended for science and sci-fi fans only.
They are all happy and cheery poems about technology, geekdom, nuclear physics, time travel, first contact and all the really important things in life. There are no soppy love poems, and no heart-felt tales of loss. These poems will make you smile and laugh and then ponder for a little while if you feel like it. At the very least, if you're a geek-nerd kind of person, they will lighten up your day.
It's a nice Christmas present for the geek in your family. Or a colleague. Or you can treat yourself.

Pre-order link: Amazon.
Warning: these poems are totally unsuited to liberal arts majors as they won't understand most of them. Recommended for science and sci-fi fans only.
Send me your HP Data Protector support contract renewal
I've made some arrangements with HPE about support contracts for Data Protector . In short, if you are about to renew your support contract -- or you think it is due soon -- send me an email (gregb@ifost.org.au) and I'll look at it.
In the past, I've often worked with customers to explain what it is that the support contract covers, identify whether there are any unnecessary line items (quite often there is) and suggest what to renew and what not to renew.
What's changed is that I can now negotiate slightly better prices on your behalf as well. So even if your contract is perfect, I should still be able to save you some money.
Greg Baker is an independent consultant who happens to do a lot of work on HP DataProtector. He is the author of the only published books on HP Data Protector (http://www.ifost.org.au/books/#dp). He works with HP and HP partner companies to solve the hardest big-data problems (especially around backup). See more at IFOST's DataProtector pages at http://www.ifost.org.au/dataprotector, or visit the online store for Data Protector products, licenses and renewals at http://store.data-protector.net/
In the past, I've often worked with customers to explain what it is that the support contract covers, identify whether there are any unnecessary line items (quite often there is) and suggest what to renew and what not to renew.
What's changed is that I can now negotiate slightly better prices on your behalf as well. So even if your contract is perfect, I should still be able to save you some money.
Greg Baker is an independent consultant who happens to do a lot of work on HP DataProtector. He is the author of the only published books on HP Data Protector (http://www.ifost.org.au/books/#dp). He works with HP and HP partner companies to solve the hardest big-data problems (especially around backup). See more at IFOST's DataProtector pages at http://www.ifost.org.au/dataprotector, or visit the online store for Data Protector products, licenses and renewals at http://store.data-protector.net/
VMware ESX 6.0 bug with CBT

VMware has announced another CBT problem. Just a reminder, this is not a problem that HPE can do anything about in Data Protector -- it's a problem with the APIs that VMware have supplied for HPE to use.
If you are doing VEAgent backups of your VMware environment (which is quite common) and you have any incrementals scheduled (also quite common), and you are running ESX 6 (which is lots of people) and you are using CBT (which you really, really would want to do normally).... then you might want to be aware that (yet again) VMware have announced that your backups could well be painfully broken.
Here's VMware's KB article:
http://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=2136854
There are several solutions:
Only do full backups. Hmm, that's a lot of data. Probably OK if you are going to a StoreOnce dedupe, but that's going to turn into a lot more tape.Turn off CBT. Ouch, that's going to hurt performance.Downgrade to ESX 5.5. I don't see anyone doing that.Using the DataProtector disk agent and automated disaster recovery module. This is actually cheaper (no extension licenses required!) and gets you both a file-level backup and an ability to restore a virtual machine from nothing. I recommend this as a better approach generally, but particularly now when we can't trust our VM-level backups.- Apply the patch that VMware has now released.
Less easy solutions, but things to think about:
- Migrate all your virtual machines to Amazon machine images. (Or Google, or Azure. Pity it can't be HP any more). It's inevitable -- eventually -- that the economies of scale of the large cloud providers will overtake your ability to run things in your own data centre. So why not start planning for it now?
- Use a different virtualisation solution. This is not the first time that VMware have announced "by the way, all backups are broken". I suspect it won't be the last time either. KVM is very mature now and it's also free. Xen is in good shape too. Virtualisation technology is no longer cutting edge -- it's commoditised now. So why not pay commodity prices?
Greg Baker is an independent consultant who happens to do a lot of work on HP DataProtector. He is the author of the only published books on HP Data Protector (http://www.ifost.org.au/books/#dp). He works with HP and HP partner companies to solve the hardest big-data problems (especially around backup). See more at IFOST's DataProtector pages at http://www.ifost.org.au/dataprotector, or visit the online store for Data Protector products, licenses and renewals athttp://store.data-protector.net/
Tuesday, 24 November 2015
Three rules of thumb that say "this job is going to take ages"
As you might know, I've written a robot called AEED which looks at work tickets and predicts how long that job is going to take. I designed it to solve the black-hole problem of service desks: instead of "we'll get back to you", it's "your request will take around 4 days". If you happen to run JIRA in the Atlassian cloud (here's the marketplace link) or HP Service Manager it's definitely worth a look.
As it turns out, it's also giving surprisingly good predictions for software development and other kinds of projects too.
Anyway, some fun: now I've got some comprehensive data across a good number of organisations.
Rule of Thumb #1: Each hand-off adds about a week.

Initially I didn't believe this: whenever I've done any sysadmin work if someone ever assigned a ticket to me and it's not something I could do anything about, I would just pass it on to someone more appropriate as soon as I saw it -- a few minutes at most.
But that's not quite it, is it? The ticket sits in your queue for a while before you get to it. Then you second guess yourself to wonder whether it really might be something you are supposed to handle and waste a bit of time investigating, during which time you will get interrupted by something more high priority, and so on. Then you might need some time to research who it is supposed to go to.
I've seen numbers as low as 4 days per re-assignment in some organisations, stretching up to two weeks for others.

Whenever an organisation gets bigger than Dunbar's Number, the mis-assignment rate starts shooting up (as can get re-assigned absurdly large numbers of times, as in the chart above). Which makes sense: no longer does anyone know what everyone is doing. (I've got a long-ish presentation about this).
Implications:
Rule of Thumb #2: Meetings slow things down.

I didn't expect that just having the word "MEETING" appearing in a JIRA ticket would be a signal for a long duration. But, wow does it ever make a difference: 8-10 standard deviations of difference in how long the ticket will take!
The actual effect is often only a few days extra, but it's a very, very definite effect.
Some people might interpret this as saying "don't have meetings, meetings are bad". I don't think this is what is going on here; if a customer or tech is writing a work ticket and mentions a meeting, it probably means that the issue really can't be resolved without a meeting. If an INTP or INTJ computer geek says that a meeting is required, it's very unlikely that they are having a meeting for the sake of having a meeting.
But, any meeting has to fit into everyone's work schedules, and that can introduce delays.
Implications:
Rule of Thumb #3. Not much gets done on Wednesday
I was digging for data that showed that Friday afternoon is the worst time to raise a helpdesk ticket because everyone would be slacking off. It turns out not to be the case at all: in all the organisations I've got, everyone is more-or-less conscientious. Perhaps they make a Friday afternoon ticket a top priority for Monday, or otherwise make up for lost time.
But Wednesday? It's not true in every organisation, but it was there for quite a few.
I can only guess why. My guess it that people have less time on Wednesdays because they are called into meetings more. Nobody would organise a meeting for a Friday afternoon if they can avoid it; likewise Monday morning is often avoided. But need to call a meeting on a Wednesday? No problem!
Does anyone have any data on this? Maybe Meekan or x.ai might know, or anyone from the Google Calendar team? Or does anyone have any good suggestions of the Wednesday effect?
Implications:
Greg Baker (gregb@ifost.org.au) is a consultant, author, developer and start-up advisor. His recent projects include aplug-in for Jira Service Desk which lets helpdesk staff tell their users how long a task will take and a wet-weather information system for school sports.
As it turns out, it's also giving surprisingly good predictions for software development and other kinds of projects too.
Anyway, some fun: now I've got some comprehensive data across a good number of organisations.
Rule of Thumb #1: Each hand-off adds about a week.
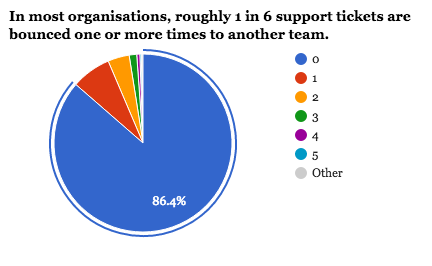
Initially I didn't believe this: whenever I've done any sysadmin work if someone ever assigned a ticket to me and it's not something I could do anything about, I would just pass it on to someone more appropriate as soon as I saw it -- a few minutes at most.
But that's not quite it, is it? The ticket sits in your queue for a while before you get to it. Then you second guess yourself to wonder whether it really might be something you are supposed to handle and waste a bit of time investigating, during which time you will get interrupted by something more high priority, and so on. Then you might need some time to research who it is supposed to go to.
I've seen numbers as low as 4 days per re-assignment in some organisations, stretching up to two weeks for others.

Whenever an organisation gets bigger than Dunbar's Number, the mis-assignment rate starts shooting up (as can get re-assigned absurdly large numbers of times, as in the chart above). Which makes sense: no longer does anyone know what everyone is doing. (I've got a long-ish presentation about this).
Implications:
- Do you know exactly who is going to do this task? If not, add a week at least.
- Is your organisation so large that it takes time just to find the right person? If so, sign-up to the next beta of AEED.
Rule of Thumb #2: Meetings slow things down.

I didn't expect that just having the word "MEETING" appearing in a JIRA ticket would be a signal for a long duration. But, wow does it ever make a difference: 8-10 standard deviations of difference in how long the ticket will take!
The actual effect is often only a few days extra, but it's a very, very definite effect.
Some people might interpret this as saying "don't have meetings, meetings are bad". I don't think this is what is going on here; if a customer or tech is writing a work ticket and mentions a meeting, it probably means that the issue really can't be resolved without a meeting. If an INTP or INTJ computer geek says that a meeting is required, it's very unlikely that they are having a meeting for the sake of having a meeting.
But, any meeting has to fit into everyone's work schedules, and that can introduce delays.
Implications:
- Do you need to meet anyone in order to complete this job? Add a few days.
- This is the kind of thing that AEED tells you. Install it now while we're still in beta and not charging for it.
Rule of Thumb #3. Not much gets done on Wednesday
I was digging for data that showed that Friday afternoon is the worst time to raise a helpdesk ticket because everyone would be slacking off. It turns out not to be the case at all: in all the organisations I've got, everyone is more-or-less conscientious. Perhaps they make a Friday afternoon ticket a top priority for Monday, or otherwise make up for lost time.
But Wednesday? It's not true in every organisation, but it was there for quite a few.
I can only guess why. My guess it that people have less time on Wednesdays because they are called into meetings more. Nobody would organise a meeting for a Friday afternoon if they can avoid it; likewise Monday morning is often avoided. But need to call a meeting on a Wednesday? No problem!
Does anyone have any data on this? Maybe Meekan or x.ai might know, or anyone from the Google Calendar team? Or does anyone have any good suggestions of the Wednesday effect?
Implications:
- Assume you have a 4.5 day week. Pretend that Wednesday is a half day, because that's about all the work you will get done on it.
Greg Baker (gregb@ifost.org.au) is a consultant, author, developer and start-up advisor. His recent projects include aplug-in for Jira Service Desk which lets helpdesk staff tell their users how long a task will take and a wet-weather information system for school sports.
Friday, 13 November 2015
My CMDB book is inappropriate
I was contacted by Apress, who wanted to publish A Better Practices Guide for Populating a CMDB. But after their editorial team reviewed it, it was deemed "inappropriate".
So if I've offended anyone because of my inappropriate writing, please accept my apologies.
Anyway, nearly two years later it's still sitting at #70 on Amazon.com.au in its category, so even if Apress don't want to sell it -- and you are interested in buying a highly inappropriate book (PDF, Kindle, etc.), then have a look at http://www.ifost.org.au/books which has links to everything I've written. Here's the spiel:
So if I've offended anyone because of my inappropriate writing, please accept my apologies.
Anyway, nearly two years later it's still sitting at #70 on Amazon.com.au in its category, so even if Apress don't want to sell it -- and you are interested in buying a highly inappropriate book (PDF, Kindle, etc.), then have a look at http://www.ifost.org.au/books which has links to everything I've written. Here's the spiel:
This guide is an in-depth look at what you should and should not include as configuration items in an IT Services model. Unlike many other books on this topic, this goes into deep technical detail and provides many examples. The first section covers some useful approaches for starting to populate a CMDB with high-level services.
The second section covers three common in-house architectures:
- What is the least amount of work you can do and still have a valid CMDB?
- What are some techniques that you can use to identify what business and technical services you should include?
- Can anything be automated to work more efficiently?
The final section details how to model applications delivered through the cloud, and what CI attributes can be useful to record. This section covers the three main types of cloud-delivered application:
- LAMP stack applications
- Modern enterprise web applications
- Relational databases, with some brief notes about other forms of database
- Software as a service applications, using Google Apps as an example.
- Platform as a service applications, using Google App Engine as an example
- Infrastructure as a service applications, using the Amazon and HP infrastructure.
Australians just dig stuff and grow stuff, and don't do tech. Here's a suggestion from the Future Party
Let's mandate farm-to-consumer tracking.
That is, as consumers of food we would like to know -- as would approximately 1 billion Chinese -- that the food we're eating has come from a healthy, responsible, sustainable farm. We would like to see a QR code on any packaging that links through to the ingredients, and where they were sourced from, and so on. For non-packaged (e.g. fruit and vegetables) there could be some other kind of sign up to give that information.
That will mean that:
That will mean that:
- Australia will lead the world in trustworthy food supplies, which will be a very, very big deal in the future.
- Provide plenty of fodder for startups to provide the technology to make it happen.
- Make Australian food just a little less competitive in the world market, easing the pressure on the dollar which will be buoyed up in the near future heavily by Chinese food purchases.
- Encourage farmers to be more proactive in automation technology.
Thanks to Markus Pfister.
Wednesday, 11 November 2015
An Atlassian story
A little while back I was talking with two Daves.
Neither had any idea of who Atlassian is or what it does, which was no surprise to me. I don't quite understand why an Australian company with $200m+ in revenue and a market cap in the billions which isn't a miner, telco or bank isn't memorable.
Still, the tools Atlassian makes are mostly used by software developers, and my circle of friends and acquaintances doesn't include many coders so "Atlassian makes the software to help people make software" isn't a good way of describing what they do.
Other than a brief stint at Google, I haven't been a full-time employee or even long-term contractor in any normal company this century, so instead I talked about what's unusual and different at Atlassian based on all the other organisations I've worked with. I talked about how the very common assumptions about the technologies to co-ordinate a business are quite different here.
And yeah, my secret superpower is to be able to narrate HTML tables in speakable form. There was a lot of "on the one hand... on the other hand at Atlassian..."
Note that the Atlassian column is all public and searchable (in line with being an open company), and the "default corporate column" is not. Also, in the Atlassian column, you opt-in to the information source; in the "traditional company" column, the sender of the information chooses who to share it with.
Why is this interesting? Because the Atlassian technologies and the Atlassian way of doing things is an immune system against office politics.
In order to get really nasty office politics, you really need an information asymmetry: managers need to be able to withhold information from other managers in order to get pet projects and favourite people promoted, and for others to be dragged down by releasing information at the worst possible moment when the other party can't prepare for it. (Experience and being middle-aged: you see far too much which you wish you hadn't.) When information is shared only with the people you choose to share it with, that's easy to do.
At Atlassian, it's not quite like that. Sure, there are still arguments and disagreements. Sometimes there is jostling for position and disagreements about direction and there are people and projects we want to see happen. And not every bad idea dies as quickly as it should. But because other interested parties can opt-in as required for their needs it's a very level playing field and ---
And that's where Dave #1 cut me off, shook my hand and said, "Wow. Thank you. That's exactly it. That's EXACTLY it."
Dave #2 just nodded sagely. "Yes," he said, and then again more slowly: "yes."
Summary: Atlassian sell office-politics treatments.
Greg Baker (gregb@ifost.org.au) is a consultant, author, developer and start-up advisor. His recent projects include a plug-in for Jira Service Desk which lets helpdesk staff tell their users how long a task will take and a wet-weather information system for school sports.
- Dave #1 is the CIO of a college / micro-university
- Dave #2 is on the board of a small airline.
Neither had any idea of who Atlassian is or what it does, which was no surprise to me. I don't quite understand why an Australian company with $200m+ in revenue and a market cap in the billions which isn't a miner, telco or bank isn't memorable.
Still, the tools Atlassian makes are mostly used by software developers, and my circle of friends and acquaintances doesn't include many coders so "Atlassian makes the software to help people make software" isn't a good way of describing what they do.
Other than a brief stint at Google, I haven't been a full-time employee or even long-term contractor in any normal company this century, so instead I talked about what's unusual and different at Atlassian based on all the other organisations I've worked with. I talked about how the very common assumptions about the technologies to co-ordinate a business are quite different here.
| Type of communication | Corporate default (aka "what most companies do") |
What is generally done at Atlassian |
|---|---|---|
| Individual-to-individual | Email or talk over coffee. | HipChat @ the individual in a room related to the topic |
| Individual-to-group | Teleconference / webinar, for all matters big or small. | A comment in the HipChat room. Or sometimes Google Hangouts and HipChat video conference if it's something long and important. |
| Reporting (project status, financials) | Excel document or similar | Confluence status page or JIRA board |
| Proposal | Word document or Powerpoint presentation | Confluence page |
| Feedback on proposals | Private conversation with the person who proposed it, or maybe on another forum page somewhere else on their sharepoint portal. | The discussion in the comments section of the confluence page. |
And yeah, my secret superpower is to be able to narrate HTML tables in speakable form. There was a lot of "on the one hand... on the other hand at Atlassian..."
Note that the Atlassian column is all public and searchable (in line with being an open company), and the "default corporate column" is not. Also, in the Atlassian column, you opt-in to the information source; in the "traditional company" column, the sender of the information chooses who to share it with.
Why is this interesting? Because the Atlassian technologies and the Atlassian way of doing things is an immune system against office politics.
In order to get really nasty office politics, you really need an information asymmetry: managers need to be able to withhold information from other managers in order to get pet projects and favourite people promoted, and for others to be dragged down by releasing information at the worst possible moment when the other party can't prepare for it. (Experience and being middle-aged: you see far too much which you wish you hadn't.) When information is shared only with the people you choose to share it with, that's easy to do.
At Atlassian, it's not quite like that. Sure, there are still arguments and disagreements. Sometimes there is jostling for position and disagreements about direction and there are people and projects we want to see happen. And not every bad idea dies as quickly as it should. But because other interested parties can opt-in as required for their needs it's a very level playing field and ---
And that's where Dave #1 cut me off, shook my hand and said, "Wow. Thank you. That's exactly it. That's EXACTLY it."
Dave #2 just nodded sagely. "Yes," he said, and then again more slowly: "yes."
Summary: Atlassian sell office-politics treatments.
Greg Baker (gregb@ifost.org.au) is a consultant, author, developer and start-up advisor. His recent projects include a plug-in for Jira Service Desk which lets helpdesk staff tell their users how long a task will take and a wet-weather information system for school sports.
Monday, 9 November 2015
Checking StoreOnce stores on Windows
In Data Protector 9.04, I've encountered a problem occasionally where the StoreOnce software store on Windows is completely unresponsive.
The error message that you will see in the session log is unpredictable, but it will often look something like this:
[Major] From: BSM@cellmgr.ifost.org.au "IFOST backup" Time: 9/11/2015 1:18:44 PM
[61:3003] Lost connection to B2D gateway named "DataCentrePrimary"
on host storeonce.ifost.org.au.
Ipc subsystem reports: "IPC Read Error
System error: [10054] Connection reset by peer
"
One of the ways of detecting the problem was that the command "StoreOnceSoftware --list_stores" would hang.
I created the following three batch files and scheduled CheckStoreOnceStatus.cmd to run once per hour:
Actually, I also added a call out to blat to send an email after the net start command.
The error message that you will see in the session log is unpredictable, but it will often look something like this:
[Major] From: BSM@cellmgr.ifost.org.au "IFOST backup" Time: 9/11/2015 1:18:44 PM
[61:3003] Lost connection to B2D gateway named "DataCentrePrimary"
on host storeonce.ifost.org.au.
Ipc subsystem reports: "IPC Read Error
System error: [10054] Connection reset by peer
"
One of the ways of detecting the problem was that the command "StoreOnceSoftware --list_stores" would hang.
I created the following three batch files and scheduled CheckStoreOnceStatus.cmd to run once per hour:
CheckStoreOnceStatus.cmd
start /b CheckStoreOnceStatusController.cmd
start /b CheckStoreOnceStatusChild.cmd
waitfor /t 600 fiveminutes
exit /b
CheckStoreOnceStatusChild.cmd
StoreOnceSoftware --list_stores
WAITFOR /SI StoreOnceOK
CheckStoreOnceStatusController.cmd
WAITFOR /T 30 StoreOnceOK && (
REM StoreOnce OK
exit /b
)
REM StoreOnce failure
net stop StoreOnceSoftware
waitfor /t 120 GiveItTime
net start StoreOnceSoftware
exit /b
Actually, I also added a call out to blat to send an email after the net start command.
So, CheckStoreOnceStatus spawns off *Controller, which will wait for 30 seconds for a signal to arrive from *Child as soon as child has been able finish StoreOnceSoftware --list_stores.
Greg Baker is an independent consultant who happens to do a lot of work on HP DataProtector. He is the author of the only published books on HP Data Protector (http://www.ifost.org.au/books/#dp). He works with HP and HP partner companies to solve the hardest big-data problems (especially around backup). See more at IFOST's DataProtector pages at http://www.ifost.org.au/dataprotector
Sunday, 8 November 2015
How to launch without venture capital
- 99.8% of all startups never raise any external capital
- Whether you raise capital or not makes absolutely no difference as to whether the startup is successful or not.
(Both facts from the QUT CAUSEE study).
It was pointed out to me recently that after 16 years of running businesses and having launched quite a few start-up technology products in that time -- without ever raising capital -- that I should try to package up my approach for other people to use.
So if you want a 2 hour Skype or Google Hangouts session with me (for AUD300+GST), just get in contact (gregb@ifost.org.au or greg_baker on Skype) and we can arrange a time. What I promise to give you is at least two or three good ideas that might get you going without having to spend stupendous sums of money.
Thursday, 5 November 2015
Pre-mortem for almost every cloud-hosted backup provider
I was talking to a vendor who wanted me to partner with them on their cloud-hosted backup solution. I looked at their pricing, and their offerings (managed storage in the cloud, DR servers in the cloud) and then compared what they could do with Amazon. Since only Google and Microsoft can compete with Amazon's scale (and then, only just), the vendor's offerings were way out of line with market rates now.
I suggested that they had three options:
I suggested that they had three options:
- They could make their product work nicely with Amazon cloud (i.e. backup to S3, manage the migration to and from Glacier). A variation would be to do this with Google Nearline Storage, which is probably a better solution, even if it doesn't have the same name recognition. They will lose a lot of revenue because there used to be margin in online storage -- but there isn't any more.
- They could migrate their entire customer base to an open source option (Bacula or BareOS). Since their customer base is going to be cannibalised anyway, they might as well make some money from the consulting effort migrating the customer somewhere else. Open source backup can still compete against cloud offerings in a couple of different ways.
- They could become roadkill.
Fortunately, they do have other sources of revenue, so hopefully they will be able to carry on. But for other specialist cloud-backup companies? I'm not sure that they many of them have a viable future.
Greg Baker is an independent consultant who happens to do a lot of work on HP DataProtector. He is the author of the only published books on HP Data Protector (http://www.ifost.org.au/books/#dp). He works with HP and HP partner companies to solve the hardest big-data problems (especially around backup). See more at IFOST's DataProtector pages at http://www.ifost.org.au/dataprotector
Subscribe to:
Posts (Atom)